This article was originally published on jdkaplan.com and is republished here with permission.
As teams mature their DevOps capabilities one of the questions that inevitably arises is this: How do we achieve traceability between deployed versions and source code? Because at some point or another, we will encounter an issue in production that doesn't seem to make sense given the code the engineering team has on hand. The goal to know, with certainty, what version of the source code aligns with the deployed system is instrumental to enabling the team to solve the right problem.
This is fairly technology-agnostic. It’s doesn’t matter if we’re building a web application, an API, a mobile app, or a command-line tool. The general concept is the same. I want be able to see a version number in the end product and know or be able to quickly find out what version of the source code and what configuration was used to create it.
There are a number of ways of achieving this. A personal favorite of mine — especially when I need a quick solution — has always been a timestamp-based approach. Other mechanisms include using the CI build number or expecting a human to manually update a version number before a build, though these approaches generally come with some downsides. In this article we’ll introduce a few such approaches and go in-depth into some of the approaches I've seen used from the quick and simple to the robust and complex.
Goals and Constraints
We’ve talked a bit about our goal of traceability, but let’s break this down into some more specific design trade-offs we might consider.
- Traceability - some way of mapping deployed systems to source code configuration.
- Eliminating human error - people make mistakes and getting people to always do something consistently is hard.
- Rollback - Enabling easy rollback to previous versions.
- Semantic Versioning - SemVer uses versions that look like
major.minor.patch. It’s a useful indication of significant or breaking changes. - Unique version numbers - Not every commit has a version, but every version should map to one and only one commit.
Approach #1: Time-based Versioning
This is my go-to lazy approach to configuration traceability. It typically involves using some variation of the date/time as the version number. A common approach is to keep a placeholder version number in the code base and replace it with a date-derived number at build time. The example below is nearly identical to the approach used for this site:
HOUR=`date "+%H%M" | sed 's/^0//'`
MONTH=`date "+%m" | sed 's/^0//'`;
VERSION=`date "+%y.$MONTH%d".${HOUR:-0}`;
sed -i.bak -e "s/\"version\": \"[0-9]*.[0-9]*.[0-9]*\"/\"version\": \"${VERSION}\"/" package.json
In this case, the version may look something like: 22.114.1200. Take a look
at the footer of this site for an example.
The benefits of this approach are that it’s easy and it provides good traceability provided your time stamps are high enough resolution to support your build frequency. What I mean by this that you mr version numbers need to be detailed enough to identify each build of your software. For example, if your version number used only year, month, and day and you were part of a team that deploys software multiple times a day, your versions would no longer map uniquely to each build.
The other downside of this approach is that the version number is mostly meaningless to your users. It doesn’t identify breaking or significant changes. This approach is fine for small teams or a personal website, but doesn’t scale well to larger teams or heavily used applications.
Another well-known example of this is the Ubuntu operating system, though it's not as granular. Ubuntu 20.04 was released in April of 2020, 20.10 is released in October of 2020 and so on.
Approach #2: Using the Build Number
This is another approach I’ve taken in the past. This involves including the CI build number in the version number somehow. A common method might be to use a manually controlled major and minor version number and use the build number as the patch number. So it would look something like this:
MAJOR.MINOR.BUILD_NUMBER
The problem I’ve found with this is that the build number typically increments sequentially in most CI systems…forever. This has two implications:
- It doesn’t reset when you update your major/minor version numbers unless you add some context awareness to your CI to know what the currently released version.
- You often end up with skipped numbers. Perhaps you do builds on your develop branch or in pull requests prior to merging code to your main branch. Or maybe you use a shared build environment with other teams. These all increment the build number causing skipped numbers in your production build.
Approach #3: Automatic Tagging and Build from Tags
This has been my go to enterprise approach. In this case we have a multi step CI/CD pipeline that leverages Git tagging. Here’s how it works:
When we build our code in our main branch, we don’t actually do a deployment. We simply build it (if we have build artifacts to save) and create a Git tag with the version number. We then have a deployment pipeline triggered by new tags with the version number that deploys our code.
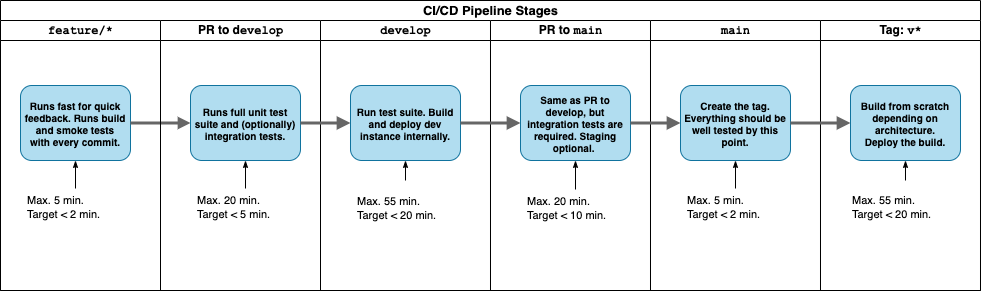
There are a few benefits here. The immediate one is we achieve perfect traceability. That is, our version of our deployed system always matches a Git tag so we can validate the source code against the live system. Second, while we do manually update the version number, by using Git tags with the version number, we can eliminate the human error of forgetting to update the version. Lastly, and possibly most important, is that it lets us revert to old version easily by rerunning our deploy pipeline (manual trigger) from a specific tag.
Concluding Thoughts
As tends to be the case in most of engineering, there isn't a single right approach. There are trade-offs that will be organization and project specific. For example on jdkaplan.com I use the timestamp approach, but for Trivium, we use the third approach for its robustness.